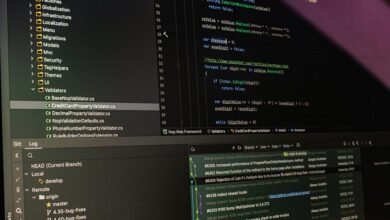
Identifier & Keyword Validation – 8334289788, anaestrada0310, Mailto Python.Org, Klgktth, Robert Mygardenandpatio
Valid identifier and keyword validation requires clear rules: identifiers start with a letter or underscore and may include letters, digits, or underscores, while keywords are reserved and must be avoided. The task examines formats such as phone-like numbers, usernames, and mailto-like strings, yet tolerates noise. A modular approach with deterministic outcomes, clear logging, and lightweight checks is essential. The discussion ends with a prompt to consider robust handling of edge cases and evolving data patterns, inviting further consideration of practical validation paths.
What Exactly Qualifies as a Valid Identifier or Keyword?
Identifiers in Python must start with a letter or underscore and can be followed by letters, digits, or underscores; keywords are reserved words that cannot be used as identifiers.
The discussion clarifies what constitutes valid identifiers and how keyword rules protect syntax.
It outlines naming conventions, case sensitivity, and reserved terms, emphasizing disciplined style and predictable behavior within programming practice.
How to Validate Common Formats: Phone Numbers, Usernames, and Mailto-like Strings
Validating common formats such as phone numbers, usernames, and mailto-like strings involves applying precise pattern checks to ensure inputs conform to expected structures. The discussion outlines how identifiers valid, keyword constraints, and lightweight patterns enable reliable validation workflows. It also highlights noisy inputs and edge cases, guiding systematic checks without ambiguity, ensuring format integrity while preserving user freedom and practical applicability.
Handling Noisy Inputs and Edge Cases Without False Positives
Noisy inputs and edge cases pose a risk of false positives unless treated with disciplined filtering.
The discussion treats handling noisy inputs and edge cases as a design constraint, not an afterthought.
Clear rules, tolerant matching, and contextual verification enable robust detection.
Sufficient logging and deterministic outcomes reduce ambiguity, promoting reliable classification while preserving freedom to adapt to evolving data patterns.
Practical Validation Workflows and Lightweight Implementation Patterns
Practical validation workflows and lightweight implementation patterns emphasize pragmatic, disciplined testing alongside minimal, reliable code paths. The approach documents procedures for valid identifiers and lightweight validation; keyword validation is integrated into practical workflows. This detached description outlines concise criteria, modular checks, and traceable outcomes, enabling teams to deploy lean validation strategies while preserving correctness, maintainability, and freedom for iterative, autonomous development.
Frequently Asked Questions
How Do Identifiers Differ Across Programming Languages and Standards?
Identifiers differ across languages in syntax, scope rules, and reserved word sets; they influence keyword restrictions and naming conventions. Identifier semantics vary, affecting readability and tooling. This impacts language portability and developer freedom, shaping cross-language interoperability and maintainability.
Can Validation Rules Conflict With International Character Sets?
Validation rules can conflict with international character sets. Conflicting encodings and locale sensitive rules may cause ambiguous normalization in internationalized identifiers, including Unicode normalization and CJK handling, challenging consistent recognition across systems while preserving freedom to use diverse scripts.
What Are Performance Trade-Offs for Real-Time Validation?
Real-time validation presents trade-offs: higher responsiveness and user feedback improve perception, but increase CPU, memory, and latency overhead. Performance validation reveals heavier processing costs, while optimized pipelines reduce latency yet may constrain feature richness and scalability.
How to Handle Ambiguous Inputs Without User Prompts?
Ambiguous inputs should be resolved through deterministic fallbacks and confidence scoring, minimizing user prompts. When uncertainty remains, the system presents transparent options and preserves autonomy, guiding decisions without coercion while maintaining traceability and predictable behavior.
Are There Security Risks in Automated Identifier Validation?
Validation security presents risks: spoofed inputs, brute-force attempts, and data leakage via improper error handling. Automated identifiers and real-time validation require robust authentication, auditing, and rate limits; ambiguous inputs demand resilient, privacy-preserving processing.
Conclusion
In summary, disciplined validation combines clear rules, modular checks, and deterministic results to distinguish valid identifiers and keywords from noisy inputs. By separating format verification (letters, digits, underscores) from context (keywords), developers achieve robust yet adaptable pipelines. The approach favors testable components, explicit logging, and predictable outcomes, reducing false positives. As in a well-tuned codebase, precision remains paramount, even as data patterns evolve—think of it as drafting a beacon in a smoky 19th-century telegraph era, guiding modern parsers onward.